Selected Publications
Full list of publications is at my Google Scholar
* indicates equal technical contribution
Deep Generative Models for Offline Policy Learning: Tutorial, Survey, and Perspectives on Future Directions
This paper is the first comprehensive review of Deep Generative Models (DGMs) for Offline Policy Learning. It covers a wide range of topics, including an in-depth analysis of five major DGMs and their applications in Offline Reinforcement Learning and Imitation Learning. The paper distills key algorithmic frameworks and paradigms, highlighting influential research works as tutorials. Additionally, it traces the development of DGM-based offline policy learning alongside advancements in generative models, providing valuable insights and future directions in the concluding summary.
Transactions on Machine Learning Research (TMLR), August 2024
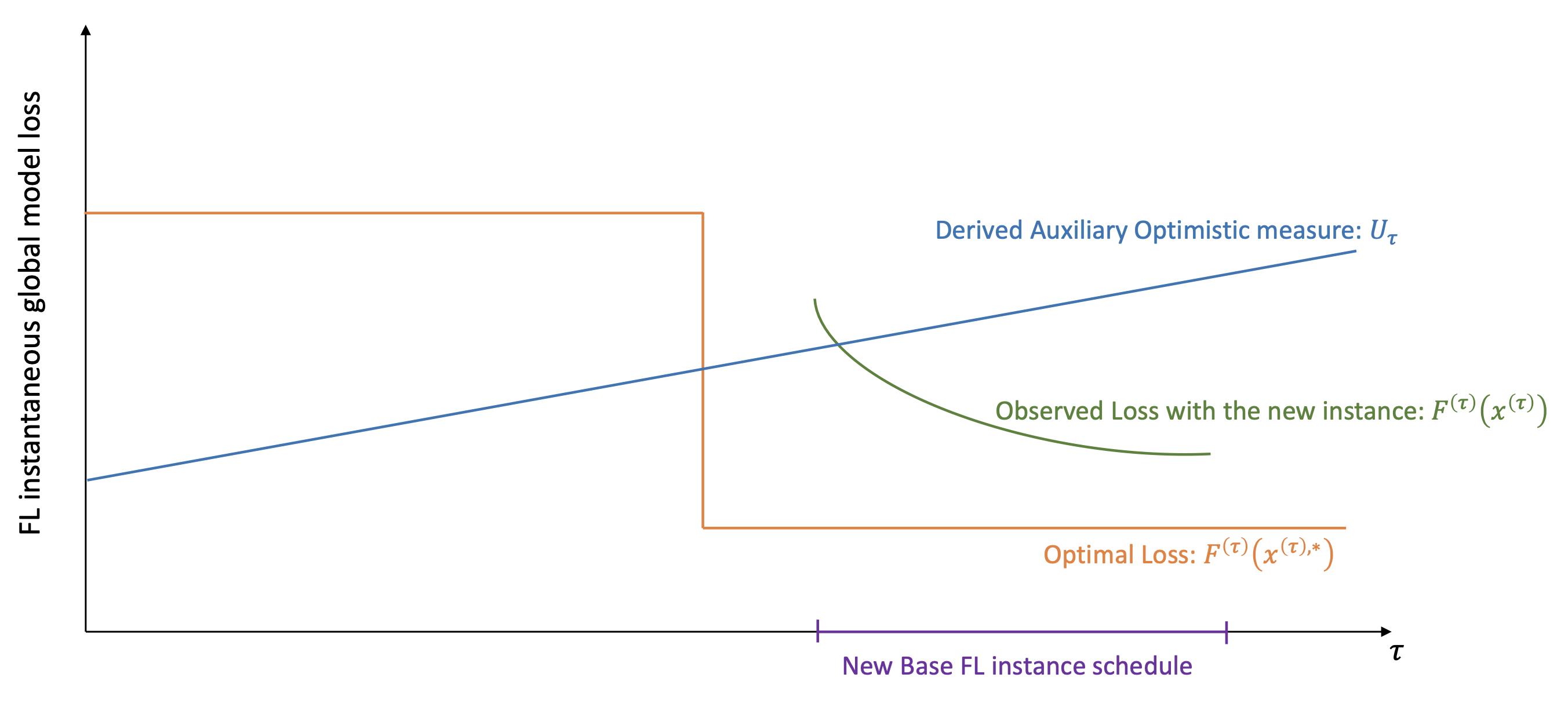
Online Federated Learning via Non-Stationary Detection and Adaptation Amidst Concept Drift
A novel multiscale algorithmic framework which combines theoretical guarantees of FedAvg and FedOMD algorithms in near stationary settings with a non-stationary detection and adaptation technique to ameliorate Federated Learning generalization performance in the presence of concept drifts.
IEEE/ACM Transactions on Networking, 2023
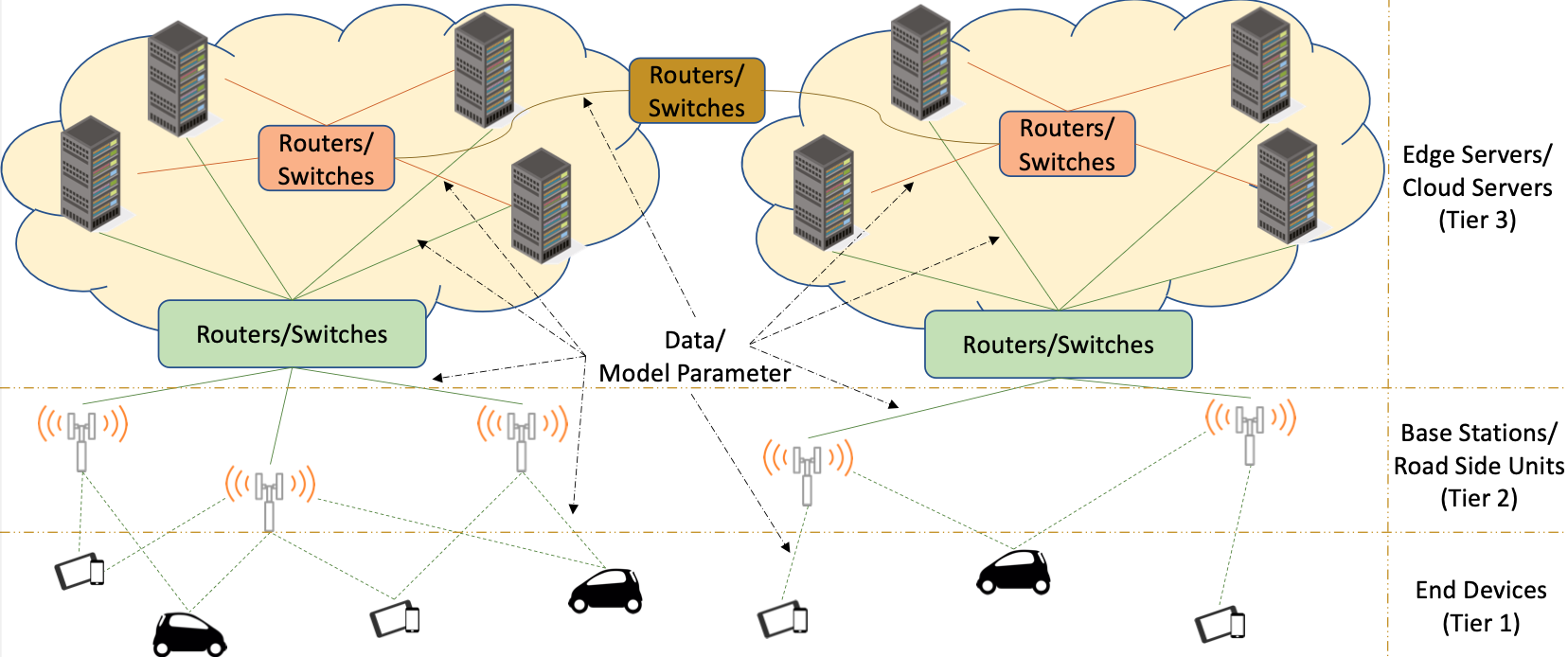
Multi-edge server-assisted dynamic federated learning with an optimized floating aggregation point
Cooperative Edge-Assisted Dynamic Federated Learning (CE-FL) introduces a distributed machine learning (ML) architecture where data is collected at end devices and model training is performed cooperatively at both end devices and edge servers. Data is offloaded from the end devices to edge servers through base stations. CE-FL features a floating aggregation point where local models from devices and servers are aggregated at a varying edge server each training round, adapting to changes in data distribution and user mobility. It accounts for network heterogeneity in communication, computation, and proximity, and operates in a dynamic environment with online data variations affecting ML model performance. We model the CE-FL process and provide an analytical convergence analysis of its ML model training.
IEEE/ACM Transactions on Networking, 2023
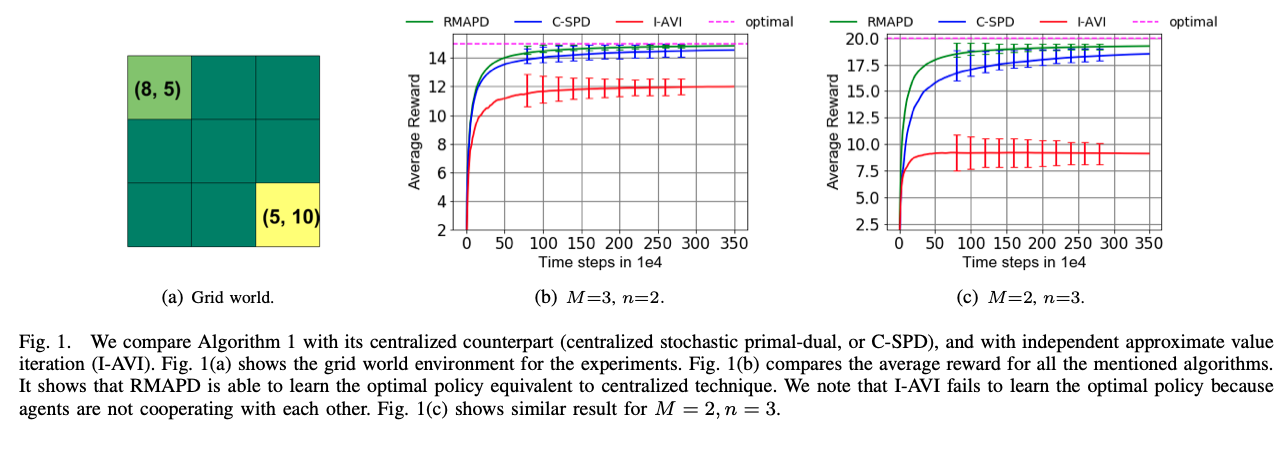
Convergence rates of average-reward multi-agent reinforcement learning via randomized linear programming
In tabular multi-agent reinforcement learning with an average-cost criterion, agents interact with the environment and observe local incentives, with the global reward as the sum of local rewards. We build upon linear programming reformulations and develop multi-agent extensions using stochastic primal-dual methods for model-free optimal sample complexity. Our approach ensures near-globally optimal solutions with sample complexity scaling appropriately with state and action space cardinality, validated by experiments.
IEEE Conference on Decision and Control (CDC), 2022
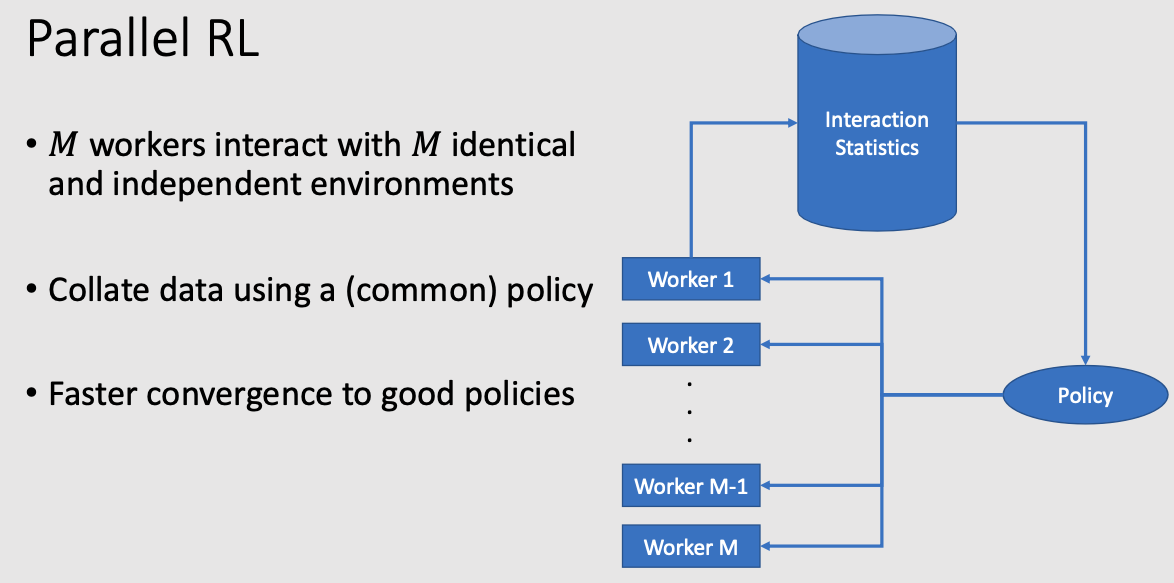
Communication efficient parallel reinforcement learning
We address a problem where agents interact with identical and independent environments using reinforcement learning, aiming to minimize regret with infrequent communication. We propose the dist-UCRL algorithm where RL agents synchronize after exceeding a threshold for state-action pair visits, resulting in favorable performance bounds along with reasonably limited communication between the agents and the environments. In Evaluations, we show that dist-UCRL performs comparably to UCRL2 with always-on communication but with significantly reduced communication.
Uncertainty in Artificial Intelligence (UAI), 2021